An Introduction to Vector Databases for Beginners

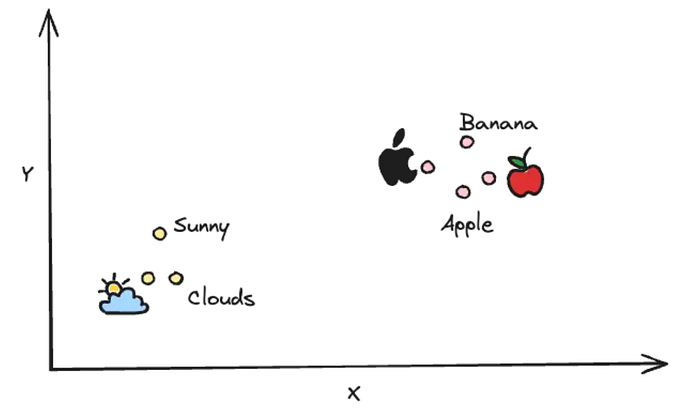
Vector databases are a type of database designed to handle and store data in the form of vectors. Vectors are essentially arrays of numbers that can represent a variety of data types, including text, images, and even audio. These databases are particularly useful in applications involving machine learning and artificial intelligence, where managing and querying high-dimensional data efficiently is crucial.
What is a Vector?
Before we dive into vector databases, let’s understand what a vector is. In simple terms, a vector is an ordered list of numbers. For example, [1, 2, 3] is a vector with three elements. Vectors can represent various types of data:
- Text: Words or sentences can be transformed into vectors using techniques like Word2Vec or BERT.
- Images: Images can be converted into vectors using convolutional neural networks (CNNs).
- Audio: Audio signals can be represented as vectors using various feature extraction methods.
Why Use a Vector Database?
Traditional databases like SQL are great for handling structured data (like tables with rows and columns), but they aren’t optimized for high-dimensional vector data. Here are some reasons why vector databases are beneficial:
- Efficient Similarity Search: Vector databases are optimized for similarity searches, making them ideal for tasks like image recognition, recommendation systems, and natural language processing.
- Scalability: They can handle large-scale data efficiently.
- Flexibility: Vector databases can manage various types of data (text, images, audio) in a unified way.
How Vector Databases Work
Vector databases store data as vectors and provide mechanisms to perform efficient similarity searches. Here’s a simplified view of how they work:
- Data Ingestion: Data is ingested and converted into vectors using machine learning models.
- Indexing: The vectors are indexed using specialized data structures like KD-trees, VP-trees, or HNSW (Hierarchical Navigable Small World) graphs to enable fast search and retrieval.
- Querying: Users can query the database to find vectors that are similar to a given vector. The database returns the most similar vectors based on a defined similarity metric (like cosine similarity or Euclidean distance).
Common Use Cases
- Image Search: Finding similar images in a large database based on a sample image.
- Recommendation Systems: Suggesting products, movies, or music based on user preferences.
- Natural Language Processing: Finding documents or sentences similar to a given text.
- Fraud Detection: Identifying unusual patterns in transactional data.
Getting Started with a Vector Database
Here’s a simple step-by-step guide to getting started with a vector database:
Step 1: Choose a Vector Database
Some popular vector databases include:
- Milvus: An open-source vector database built for scalable similarity search.
- Pinecone: A fully managed vector database service.
- Faiss: A library for efficient similarity search and clustering of dense vectors developed by Facebook AI Research.
Step 2: Install and Set Up
For this tutorial, let’s use Milvus. You can install Milvus using Docker. Here’s how:
- Install Docker: Follow the instructions on the Docker website.
- Pull Milvus Docker Image: docker pull milvusdb/milvus:latest
- Start Milvus: docker run -d — name milvus -p 19530:19530 -p 19121:19121 milvusdb/milvus:latest
Step 3: Ingest Data
Convert your data into vectors using appropriate models and ingest them into Milvus. For instance, you can use the following Python code snippet to connect to Milvus and insert vectors:
from pymilvus import connections, Collection, utility
# Connect to Milvus
connections.connect(alias="default", host="127.0.0.1", port="19530")
# Define a collection schema
fields = [
{"name": "embedding", "type": DataType.FLOAT_VECTOR, "params": {"dim": 128}},
{"name": "id", "type": DataType.INT64, "is_primary": True}
]
collection_name = "example_collection"
collection = Collection(name=collection_name, schema=fields)
# Insert vectors (example with random vectors)
import numpy as np
vectors = np.random.rand(1000, 128).tolist()
ids = [i for i in range(1000)]
collection.insert([vectors, ids])Step 4: Query the Database
You can query the database to find similar vectors. Here’s an example of how to perform a search:
# Define a query vector
query_vector = np.random.rand(1, 128).tolist()
# Perform a search
search_params = {"metric_type": "L2", "params": {"nprobe": 10}}
results = collection.search(query_vector, "embedding", search_params, limit=5)
for result in results:
print(result)Conclusion
Vector databases are powerful tools for handling high-dimensional data, especially in AI and machine learning applications. They offer efficient similarity search, scalability, and flexibility, making them suitable for various use cases such as image search, recommendation systems, and natural language processing.
By following this tutorial, you should have a basic understanding of what vector databases are, why they are useful, and how to get started with one. If you have any questions or need further assistance, feel free to reach out!
Happy learning!
Written by: Vector Database for Dummies